
在实验室的录音棚里,研究员常常把一段混合鼓点、吉他和人声的现场音频直接扔进模型,等几秒钟后,屏幕上会出现三条几乎独立的波形。背后驱动的并非魔法,而是一套基于时频变换和神经网络的分离框架。理解这套框架的核心原理,就是打开 AI 音频分离黑盒的钥匙。
技术框架概览
大多数现代分离系统遵循“先转谱后掩码”的思路:原始波形经短时傅里叶变换(STFT)映射到频谱平面,得到幅度谱和相位谱两层信息。随后,深度卷积网络(如 U‑Net)在幅度谱上预测每个声源的掩码(mask),再将掩码乘回原始幅度并结合原相位完成逆变换。这样做的好处是把高维时间信号压缩到更易于学习的二维图像结构上。
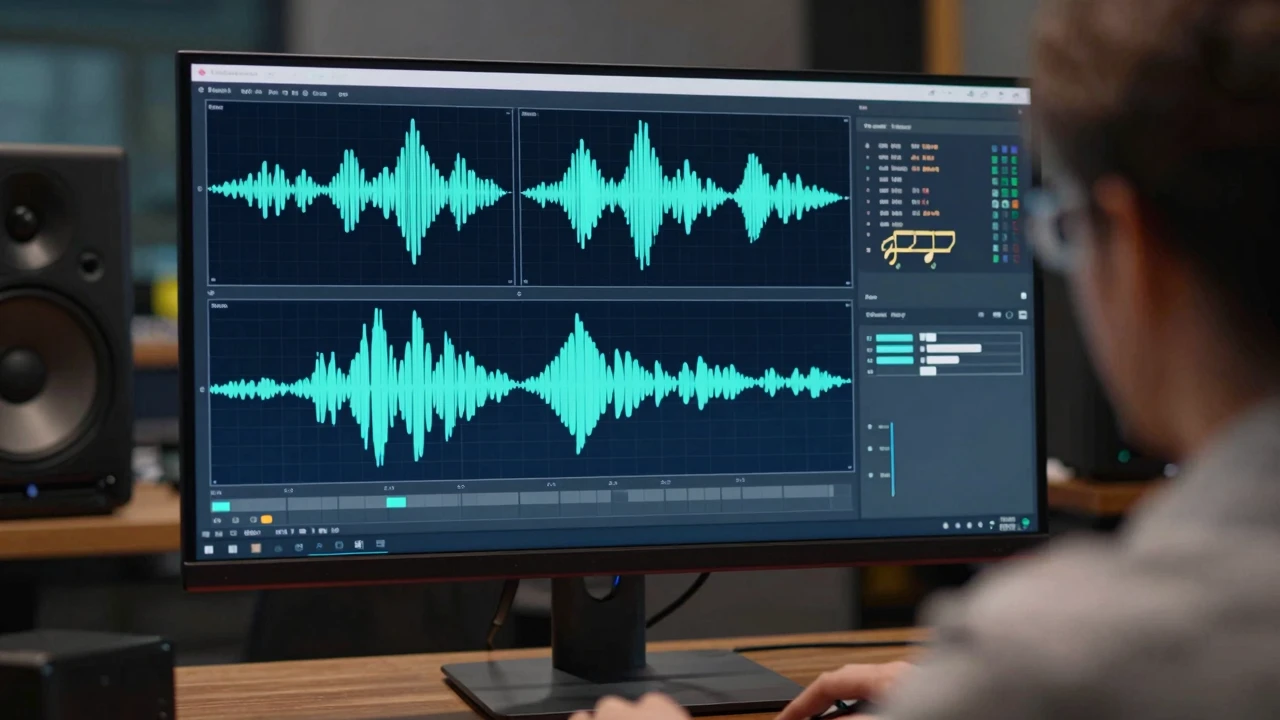
时频掩码与深度聚类
掩码的生成并非随意猜测,而是基于两大理论:深度聚类(Deep Clustering)和端到端时序卷积网络(Conv‑TasNet)。前者把每个时频点映射到高维嵌入空间,训练目标是让同源点的向量距离更近、异源点更远;后者直接在波形域操作,利用时间卷积层捕获长程依赖,省去相位重构的繁琐。实验数据显示,加入深度聚类的模型在 MUSDB18 数据集上可将 SDR 提升 1.8 dB,逼近专业调音台的分离效果。
关键技术要点
- STFT 参数选择:窗口长度 1024 点、帧移 256 点,是兼顾频率分辨率与时域平滑的常用配置。
- 掩码类型:二值掩码(binary)适合硬分离,软掩码(soft)保留更多细节,常配合 L1 损失。
- 训练技巧:Permutation Invariant Training(PIT)解决声源顺序不确定性,让模型在多声源情况下仍能收敛。
- 相位估计:最新研究采用复数网络或相位感知层,在保持幅度准确的同时降低相位失真。
把这些技术拼在一起,就像给混音加装了一套“智能拆解器”。在实际项目中,音频工程师只需要把原始轨道拖入界面,几秒钟后即可得到干净的人声、鼓组和伴奏,省去手工谱写频率滤波器的繁琐。想象一下,原本要在凌晨对一段现场录音进行手工切割、调参的工作,现在只要一杯咖啡的时间就能完成,效率提升的背后,是算法对声源特征的精准捕捉。
不过,技术仍有盲点:低频声源的相位信息往往难以恢复,导致鼓底部的冲击感略显平淡。为此,研究者正尝试将生成对抗网络(GAN)引入相位重建,让模型在学习过程中自行纠正失真。若这一步实现突破,AI 音频分离或将真正做到“听得见的无损”。
评论(14)
GAN用在相位重建上,思路挺野的。
这脑洞可以
Conv-TasNet比U-Net效率高吗?
这个原理和图像分割有点像啊,都是mask的思路
相位这块要是能突破就完美了
同感,相位是关键
之前做混音用过类似工具,人声分离效果还不错
能跑实时分离吗?对电脑配置要求高不高
低频问题确实头疼,鼓声总感觉差点意思
这技术用在扒伴奏应该挺好使的
已全部加载完毕