
处理人声齿音(Sibilance)是混音中最让人头疼的环节之一。传统的多段压缩或宽带去齿音插件虽然能解决问题,但往往会带来一种"被捂住嘴"的沉闷感,牺牲了人声的空气感与穿透力。动态EQ的介入,本质上是一场从"粗暴切除"到"外科手术"的技术进化,其核心在于对频域信号的动态阈值控制机制。
频域动态控制的底层逻辑
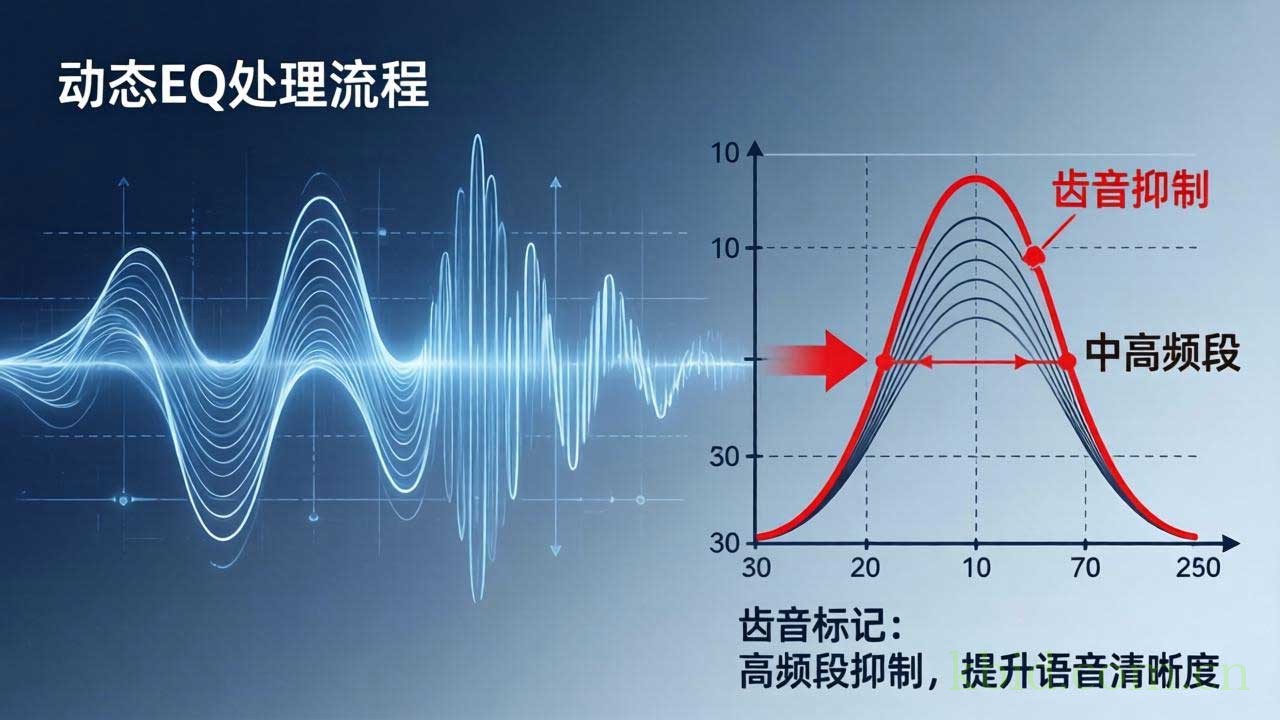
普通的参数均衡器是静态的——你设定好衰减6dB,它就无差别地衰减6dB,无论该频段信号能量是强是弱。这导致当齿音消失时,人声中那些必要的高频泛音(如2kHz-10kHz带来的明亮度)也被一并削减,声音变得黯淡无光。
动态EQ则引入了类似压缩器的侧链(Sidechain)检测机制。具体来说,它会在特定频点(通常为5kHz-8kHz)设置一个带通滤波器作为检测回路。当该频段的信号电平超过预设阈值(Threshold)时,均衡器才会触发衰减动作;一旦信号回落,增益衰减便会自动释放,频率响应曲线回归平直。这种"按需处理"的特性,保留了齿音间隙的正常高频细节,避免了"一刀切"带来的音色污染。
时间常数与听感伪影
动态EQ处理齿音的成败,往往取决于 Attack(启动时间)和 Release(释放时间)的参数设定,这远比选择切哪个频点复杂得多。
- 启动时间:齿音的瞬态极快,通常只有几十毫秒。如果Attack过慢(如超过20ms),齿音的尖锐头部的能量已经通过,衰减动作却还没跟上,导致处理失效或产生"咔嗒"声;若Attack过快,则可能引发相位畸变,导致高频听起来像被"削波"一样生硬。通常,0.1ms-5ms是较为安全的区间。
- 释放时间:这是决定声音是否自然的关键。过短的Release会引发低频调制失真,而过长的Release会让衰减持续时间过长,导致齿音后的元音(如"si"后的"i")变得发虚、发干。自适应释放算法在这里显得尤为重要,它能根据信号持续时长自动调整恢复速度。
Q值与滤波器斜率的影响
很多人在设置动态EQ时习惯使用极窄的Q值(如Q=30),试图精准打击齿音频点。这种做法在数字域中极其危险。过窄的滤波器会产生极高的共振峰,即便是在非衰减状态下,也会改变信号的相位响应,带来"金属味"染色。经验表明,使用适中的Q值(Q=2至Q=6),配合稍宽的带宽,往往能获得更自然的听感。毕竟,齿音并非单频信号,而是一段宽频带的高频噪声,稍微宽一点的"手术刀"反而能切得更平滑。
真正专业的齿音处理,不是让"s"和"t"彻底消失,而是将它们从刺耳的尖锐噪音,驯化为人声表情的一部分。动态EQ提供的,正是这种在"控制"与"保留"之间寻找微妙平衡的可能性。
评论(15)
看完感觉脑子会了,手还没会。
这就是我想要找的教程,感谢!
还得是动态EQ,普通的切完听着真别扭。
0.1ms到5ms这个区间回去试试看。
终于讲清楚原理了,之前都是瞎调。
所以到底是用动态EQ还是专门的DeEsser啊?
那个“被捂住嘴”的形容太贴切了哈哈哈。
已全部加载完毕