第一次在工作室里打开Virta的界面,耳边的合成声像是被一只无形的手轻轻敲击,瞬间出现了与人声相似的共振峰。这个现象并非偶然,而是背后一套精细的实时共振建模算法在发挥作用。
核心物理模型:基于管道波导的共振腔
Virta采用了可变长度的数字波导(Digital Waveguide)来模拟声道的管道结构。声波在波导中来回反射,形成若干驻波点,这些驻波对应了人声的基频与泛音。通过动态调节波导的延迟采样数,系统能够在毫秒级别内实现声道长度的变化,从而模拟说话时口腔、喉部的实时形变。
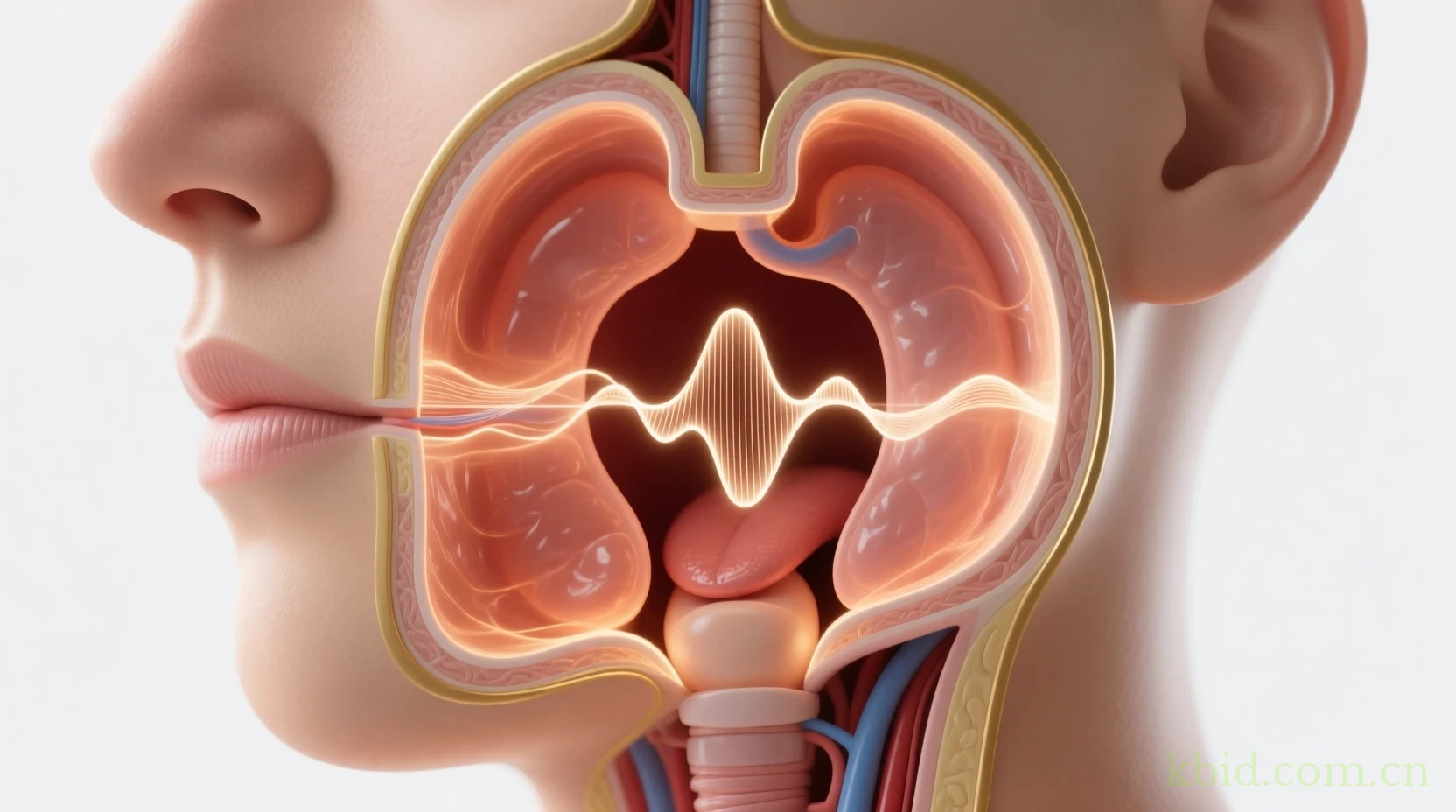
实时信号流:分层滤波与瞬时谱估计
输入的原始音频先进入一个多段带通滤波网,每段对应一个共振峰的频率范围。随后,Virta使用改进的短时傅里叶变换(STFT)结合相位锁定技术,提取瞬时频率与幅度信息。关键在于它把每个滤波段的能量反馈到波导的阻尼系数上,使得共振峰随演奏者的发声力度自动加深或衰减。
调制与交互:多维控制信号的融合
除了音频本身,Virta还接受 MIDI、CV 以及内部 LFO 的调制信号。举例来说,给波导的延迟参数喂入一个慢速的三角波,口腔长度就会像呼吸一样周期性伸缩;把一个高频噪声映射到阻尼系数,则能在瞬间制造出嘶嘶的喉音。说白了,这相当于给声道装上了“可编程的肌肉”。
- 波导长度 → 基频控制
- 阻尼系数 → 泛音衰减
- 多通道滤波 → 频段分离
- 实时谱估计 → 动态共振追踪
正是这些技术的叠加,让Virta在不到 10 ms 的总延迟下,完成了从原始声波到共振强化再回到输出的完整闭环。于是,声音在电路里找到了自己的回声。
评论(16)
工作室用这个效果咋样?
阻尼系数映射那段没太看懂
感觉这算法用在唱歌上会很赞
有人试过用这个做语音合成吗?
实时建模能做到10ms也太强了吧
波导长度具体怎么调?
之前调过类似插件,延迟确实难搞
这技术原理看得我头大🤯
已全部加载完毕